LevelDBではキーバリューデータを内部的に効果的に扱うキャッシュ機構が実装されています。
LevelDBのキャッシュは”/include/leveldb/cache.h”でインターフェースが定義されており、実装は”/util/cache.cc”でShardedLRUCacheクラスとして行われています。
キャッシュ処理の分散
ShardedLRUCacheはキャッシュ操作を排他的に行うためのロック処理の効率化を行うために、実際のキャッシュを行うLRUCacheインスタンスを複数管理し、ハッシュ値によって、処理を行うLRUCacheオブジェクトを決定します。
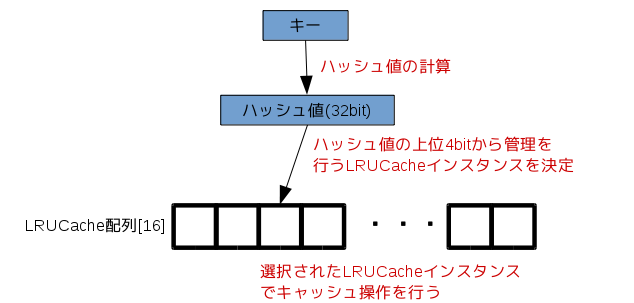
ShardedLRUCacheがデータ操作のためにキー情報を受け取ると、キーからハッシュ値を算出します。
ShardedLRUCacheが管理を行うLRUCacheインスタンスは16要素の配列として管理されているので、ハッシュ値の上位4bitを用いて処理を行うLRUCacheインスタンスを決定します。
このように排他ロックを伴うハッシュ管理を複数のインスタンスへ分散することによって排他制御によるボトルネックを軽減しています。
キャッシュ管理
LevelDBのキャッシュ機構は、一般的なチェイン法によるハッシュテーブルと、LRUによるリソース管理がLRUCacheクラスで実装されています。
キャッシュ要素
まずキャッシュを行うデータ要素はLRUHandle構造体によって行われます。以下にLRUHandle構造体の定義を記述します。
struct LRUHandle { void* value; void (*deleter)(const Slice&, void* value); LRUHandle* next_hash; LRUHandle* next; LRUHandle* prev; size_t charge; // TODO(opt): Only allow uint32_t? size_t key_length; bool in_cache; // Whether entry is in the cache. uint32_t refs; // References, including cache reference, if present. uint32_t hash; // Hash of key(); used for fast sharding and comparisons char key_data[1]; // Beginning of key };
|
LRUHandle構造体のkey_dataでキャッシュデータのキー、valueでバリューへの参照をそれぞれ管理します。
その他の要素はハッシュテーブルやLRUの管理のために用いられます。
ハッシュテーブル
LevelDBではキャッシュされたデータを高速に検索するために、キャッシュデータをチェイン法によるキャッシュテーブルで管理しています。キャッシュテーブルの実装はHandleTableクラスで行われています。
またキャッシュテーブルのサイズは固定ではなく、格納要素がキャッシュテーブルのサイズより大きくなる度に、キャッシュテーブルのサイズを2倍に拡張するようになっています(キャッシュテーブル位置をビット演算で検出するためにサイズは2の乗数とします)。
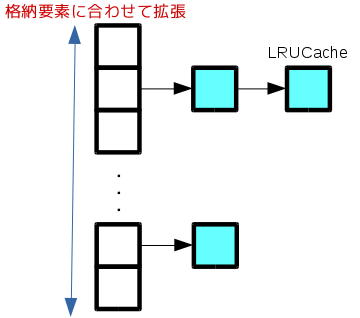
LRUHandle構造体のnext_hashメンバを用いて、ハッシュリストの管理しています。
LRUによるリソース管理
キャッシュ機構は、特定のメモリ領域内でデータを保持するようになっています(始めに利用するメモリ領域を指定します)。そのためメモリ領域以上のデータをキャッシュを行おうとすると、他のデータをキャッシュから離脱させます。この時にLRUによって離脱するデータを管理するようになっています。
LevelDBでは以下の図に示す2つの双方向リンクリストによってリソースを管理します。
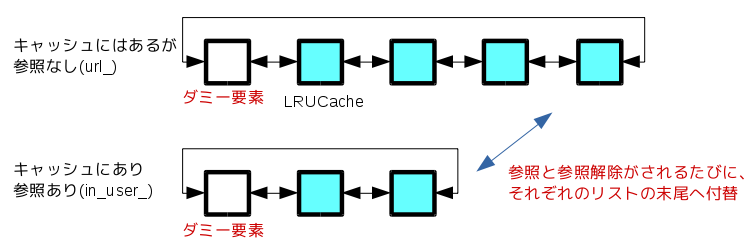
まず1つ目はlru_メンバによって管理されるキャッシュにあって参照がされていない要素のリストで、2つ目はキャッシュにありユーザに参照されている要素のin_user_リストです。
任意の要素はユーザによる参照が行われるとlru_リストから、in_user_リストの末尾へと移動します(LRUHandle構造体のrefsで参照すうを管理)。その後、ユーザによる参照が無くなるとin_user_リストからlru_リストの末尾へ移動されます。
以上のことからlru_リストの先頭要素ほど、参照され無くなってから時間が経過している要素となるため、キャッシュのメモリ容量以上のデータの挿入が発生すると、キャッシュから離脱させる要素の対象となります。
ちなみに要素の挿入時と要素に対する検索が行われたときに、参照がされたと判断されます。
このようにLevelDBではキャッシュテーブルとLRUアルゴリズムによってキャッシュ機構を実現しています。