ここではBrokerが受けったメッセージをディスクへ書き込んで管理するためのログ機構について説明を行っていきます。
ソースコードは”src/main/scala/kafka/log/”ディレクトリ内のファイルに対応します。
ログの格納
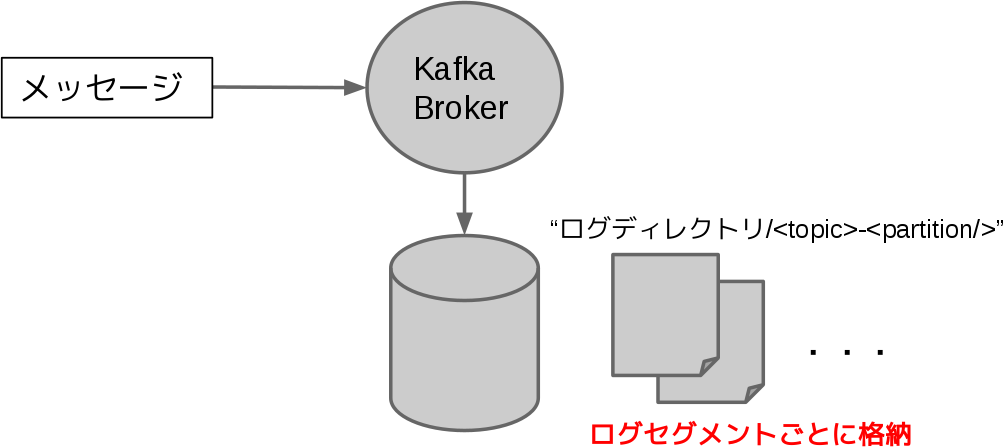
メッセージをまとめてログファイルとしてディスクに書き出すディレクトリは、プロパティ”log.dirs”(もしくは”log.dir”)で指定したディレクトリ(ログディレクトリ)以下の”<トピック名>-<パーティション>“ディレクトリ内に格納されます。
新規でトピックを作成した場合などにログファイルを新規で作成しますが、ログディレクトリを複数指定していた場合には、最も作成されている数(ログディレクトリ内のディレクトリ数)が少ないログディレクトリを作成対象として選択します。
ログセグメント
ログは1つのファイルに逐次書き込まれていくのではなく、複数のファイルに分割されながら書き込まれていきます。この分割の単位をログセグメントと呼びます。
以下の図のように、受け取ったメッセージをログとして書き込んでいきます。
ログセグメントの構成
さてこのログセグメントは3つのファイルから構成されます。
1つはメッセージを格納していくログファイル、さらにメッセージの読み込み時に参照するためのオフセットインデックス(OffsetIndex)とタイムインデックス(TimeIndex)です。
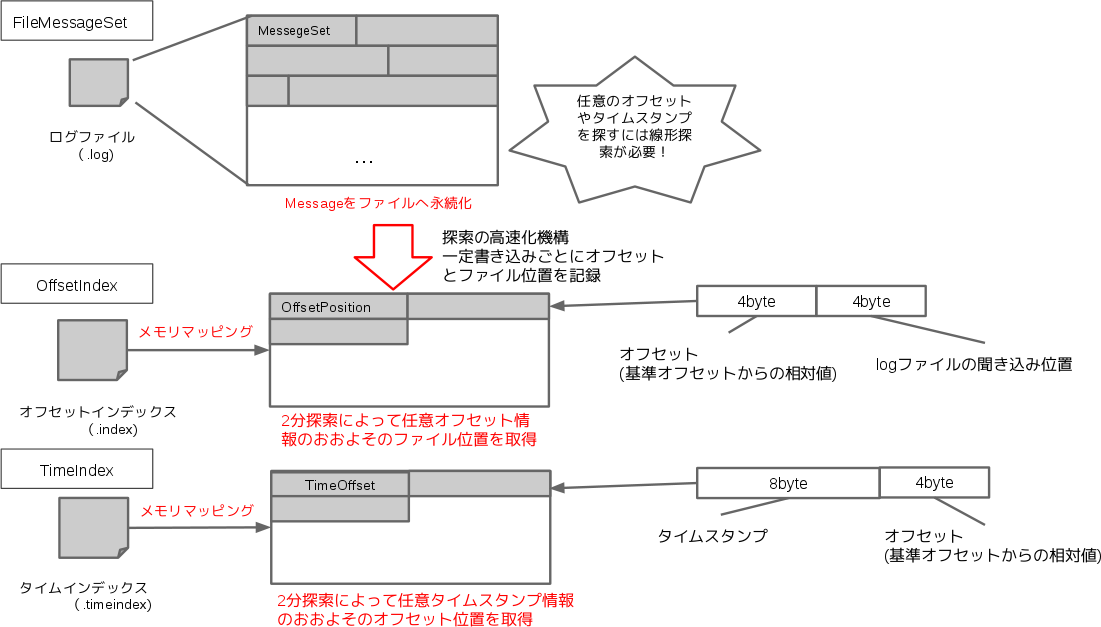
ログ機構では書き込みの単位をメッセージ処理で説明したMessageSetというメッセージの集合として受け取ります。このMessageSetを書込みデータとして受け取るとログファイルの末尾への書込みが行われます。
一定量(プロパティ”log.index.interval.bytes”で指定したバイト数)ごとの書込みが行われると現在のオフセットと、そのオフセットに対応するメッセージがログファイルのどこに記述されているかの書込み位置をオフセットインデックスへ格納します。また現在のタイムスタンプとオフセットの情報をタイムインデックスへ格納します。
ただしインデックスファイルへ書き込まれるオフセットの値はオフセットのそのものの値ではなく、オフセットと基準オフセットと呼ばれるログファイルに最初に書かれたオフセットとの差分の値が書き込まれることになります。
インデックスファイルを作成することによって、任意のオフセットやタイムスタンプのメッセージを取得する処理が高速に行えるようになります。
インデックスファイルが存在しない場合には、ログファイルの先頭からシーケンシャルスキャンによって対応するオフセット(もしくはタイムスタンプ)のメッセージを捜さなければなりません。
しかしインデックスファイルがあると、まずインデックスファイルの内容から2分探索(オフセットは短調増加していくので2分探索が可能になります)によって、オフセットに対応するメッセージがメッセージファイル内のどこに位置するかがおおよそでわかるため、シーケンシャルスキャンを行わなけばならない範囲を限定することが出来ます。
このようにインデックスファイルを作成することによって読み込み処理が効率的に行われるようになります。インデックスファイルへの書き込みの閾値であるプロパティ”log.index.interval.bytes”を小さくすればより効率的に読み込みが行えますが、インデックスファイルが大きくなったり、書込み処理が重くなったりとトレードオフがあることに注意する必要があります。