ここではKafkaのメッセージについて記述していきます。
Kafkaではproducerから受け取ったメッセージをlogとしてディスクに書き込みながら管理を行います。
ログディレクトリ
そのデータはプロパティファイルの”log.dirs”プロパティで指定したディレクトリ(以下、ログディレクトリ)で管理されることになります。プロパティで指定するログディレクトリは1つでなくて複数でも可能で、CSVと同様にカンマ「,」区切りで記述します(ログディレクトリを1つしか指定しない場合には”log.dir”プロパティでも指定することが出来る)。
メッセージ構造
producerから受け取ったメッセージはTopicとPartitionごとに管理されます。
Topicはproducerから明示的に指定しますがPartitionは内部で自動的に割り当てられます。メッセージのTopicとPartitionが決定すると、そのメッセージはログディレクトリの「<Topic>-<Partirtoion>」に対応するディレクトリ内に格納されることになります。
1つのメッセージはMessageクラストして管理されます。以下にMessage構造についての図を示します。ソースコードでは”src/main/scala/kafka/message/message.scala”に対応します。
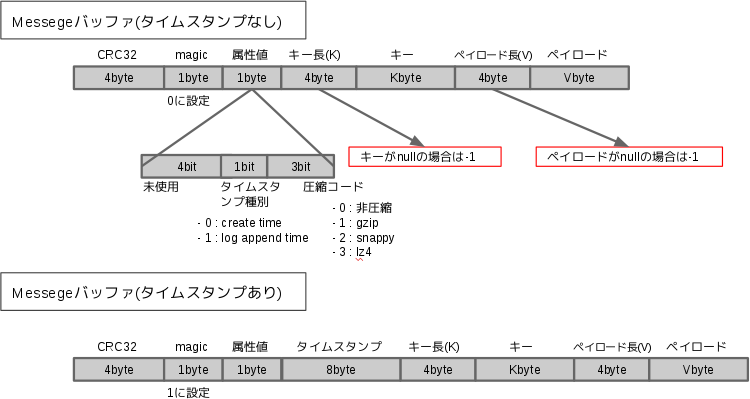
Kafkaではバージョン0.10から、メッセージに対してタイムスタンプを付与出来るようになりました。そのためMessage構造はメッセージにタイムスタンプを付与するかどうかで、少し異なります。メッセージにタイムスタンプを付与しない場合にはmagicの値が0、付与する場合には1を格納します。
Message構造は一般的なキーバリューストアと同様にキーとペイロード(後述しますがバリュー値以外も圧縮されたメッセージも格納されます)とそのほかの情報から成り立ちます。
細かく見ていくと図中のCRC32は、メッセージ誤り検出のためのチェックサム値、magicにはマジックナンバー(メッセージにタイムスタンプを付与するかどうかで0か1が格納)、属性にはペイロードの圧縮を示すための値とタイムスタンプに関する情報がそれぞれ格納されます。またタイムスタンプを付与する場合には属性値の後に8byteのタイムスタンプ情報が加わります。
Messageペイロードの圧縮方法について見ていくと、属性値の下位3bitで圧縮コードが表され、0が未圧縮であることを示し、1がgzip,、2がsnappy、3がlz4の圧縮方法でそれぞれ圧縮されていることを表しています。
メッセージセット(非圧縮)
複数のメッセージをログディレクトリへと格納する際には、先程のMessages構造とは別にメッセージごとにユニークな値(ここではTopic-partitionごとにユニークな値)であるOffsetが割り当てられます。Offsetはメッセージに対してシーケンシャルに割り当てられる値と解釈出来る。
以上のことから、複数のメッセージをlogとしてログディレクトリ格納すると以下の図のようになります。ここでは圧縮をしない場合についてのパターンを示しています、
Kafkaでは1つずつのメッセージをその都度、ログディレクトリへ書き込むのではなく、いくつかのメッセージをまとめて(メッセージセットごとに)書き込むようになっていて、複数のメッセージをMessageSetオブジェクトとして扱います。ソースでは”src/main/scala/kafka/message/MessageSet.scala”や”src/main/scala/kafka/message/ByteBufferMessageSet.scala”に対応します。

このようにKafkaではproducerから受け取ったメッセージをまとめてログディレクトリへ書き込んでいきます。