Kafkaメッセージ処理(1)では、メッセージ構造から非圧縮のメッセージセットまでを説明しました。ここでは主に圧縮を行った場合のメッセージの扱いについて記述を行います。
メッセージセット(圧縮)
まずKafkaメッセージ処理(1)で記述した、非圧縮の場合のメッセージセット構造を改めて以下に示します。

このように圧縮を行わなかった場合にはメッセージにオフセットとメッセージ長を付加して並べているだけでした。
メッセージを圧縮した場合には上で示したメッセージ集合を圧縮したものを、ペイロードとして持つメッセージを作成します。以下に圧縮した場合のメッセージについての図を示します。
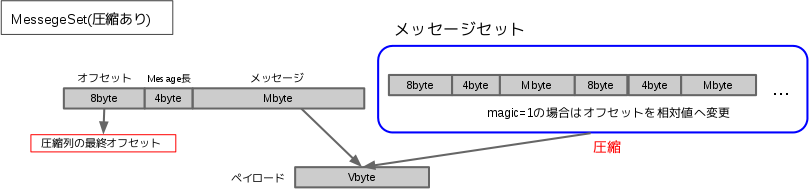
図のように、圧縮を行った場合にはメッセージ集合を圧縮したものをペイロードとして格納した1つのメッセージとなります。ここで圧縮メッセージをペイロードとしてもつメッセージに割り当てるオフセットの値は、圧縮されたメッセージ集合の最後のメッセージのオフセットと同じ値を格納します。また圧縮を施すメッセージ集合のmagic値はすべて同じ値となり、magic値が1の場合にはメッセージ集合内のオフセットの値が、先頭のメッセージからの差分の値が格納されることになります。
このようにしてメッセージを圧縮することによって、圧縮されていないメッセージと構造が同じになり内部的な処理が行いやすくなります。
メッセージのイテレート処理
圧縮をする場合も、しない場合もメッセージ集合は同じような構造で格納することになるます。そのため1つ1つのメッセージを読み込む際の処理は、まずメッセージのメタ情報として格納されている圧縮コードを見て、そのメッセージが圧縮されおらずペイロードにデータが格納されているのか、圧縮されたメッセージ集合がペイロードに格納されているのかを判断します。圧縮されたメッセージ集合を持つ場合にはペーロードに対してデコードを施し、格納されていたメッセージ集合をさらにイテレートしていきます。
shallowイテレートとdeepイテレート
メッセージ集合をイテレートしていく処理ですが、格納されているメッセージを1つ1つ取り出していく場合には圧縮されたメッセージをデコードしながらイテレートしていく必要がありますが、一方でメッセージ集合のサイズが全体でどれくらいになるのかを知りたい場合は圧縮されたメッセージをデコードせずに圧縮メッセージ集合をペイロードとしてもつメッセージを1つのメッセージをそのままイテレートしていけば良いことになります(メッセージをディスクに書き込む場合などはメッセージを圧縮したまま書き込みを行うことになるので、この場合は圧縮された場合のメッセージ集合のサイズを調べます)。
このように圧縮されたメッセージを展開しないでイテレートしていく機構がshallowIterator、圧縮されたメッセージを展開しながらイテレートする機構がdeepIteratorとして、それぞれ実装されています。以下はshallowイテレートとdeepイテレートの違いを示した図です。
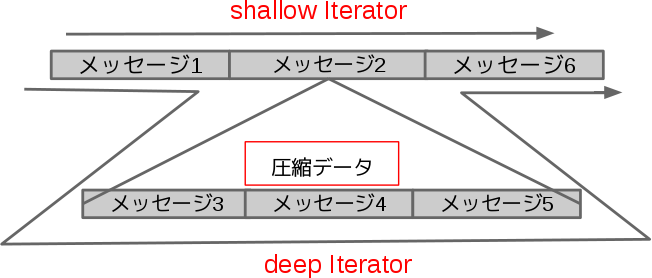
図のように”メッセージ1″から”メッセージ6″までがあるとします(簡易化のためオフセットなどは省略しています)。deepイテレートではメッセージの1,3,4,5,6と圧縮されたメッセージを展開しながらメッセージを返していきます。一方でshallowイテレートの場合には圧縮を展開しないため1,2,3という順番でメッセージを返します。